字符串哈希
定义
字符串哈希就是通过一种计算方法,将每个不同的字符串映射成不同的数值。
算法流程
- 把字符串映射成一个 p 进制数字。
对于一个长度为 n 的字符串 s,
这样定义 Hash 函数:h(s) = ∑(i=1 to n) s[i] × p^(n-i) (mod M)
例如,字符串 abc,其哈希函数值为a*p^2 + b*p^1 + c
即97 × 131^2 + 98 × 131^1 + 99 - 如果两字符串不一样,Hash 函数值却一样,这样的现象称为哈希碰撞。
- 解决哈希碰撞的方法:
(1) p 通常取质数 131 或 13331
(2) M 通常取大整数 2^64,把哈希函数值 h 定义为 ULL,超过则自动溢出,等价于取模。
求一个字符串的哈希值相当于求前缀和,求一个字符串的子串的哈希值相当于求区间和。
最小表示法
定义
当字符串 S 中选定一个位置 i 满足 S[in] + S[1i-1] = T,则 T 是 S 的循环同构串。
设 S = “BCAD”,其循环同构串有“BCAD”、“CADB”、“ADBC”、“DBCA”, 当 i=3 时,得到字典序最小的循环同构串是“ADBC”。
最小表示法就是找出字符串 S 的循环同构串中字典序最小的那一个。
对于循环串(或环),通常的技巧就是复制一倍,破环成链,然后扫描。 用三个变量指针控制扫描,指针 i,j 控制匹配起始位置,指针 k 控制匹配长度。
算法流程
- 把字符串复制一倍
- 初始化指针 i=1,j=2,匹配长度k=0;
- 比较s[i+k]和s[j+k]是否相等,
(1)s[i+k]==s[j+k],则 k++;
(2)s[i+k]>s[j+k],则 i=i+k+1;
(3)s[i+k]<s[j+k],则 j=j+k+1;
若跳转后两个指针相同,则 j++,以
确保比较的两个字符串不同; - 重复上述过程,直到比较结束;
- 答案为 min(i, j)。
1 |
|
KMP
给定一个模式串P和一个主串S,求模式串P在主串S中出现的位置。(字符串的下标均从1开始)
- 取最长的相等前后缀,可以保证不漏解。
- 通过模式串前后缀的自我匹配的长度,计算 next 函数,给 j 指针打一张表,失配时就跳到 next[j] 的位置继续匹配。
next函数
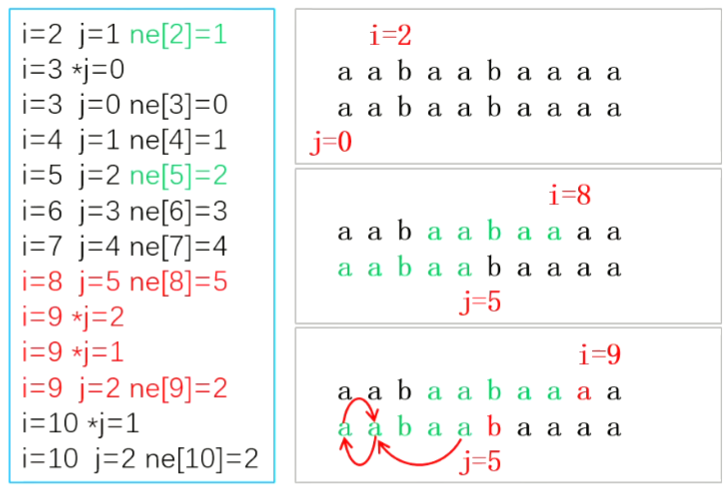
next[i] 表示模式串 P[1..i] 中相等前后缀的最长长度
P a a b a a b a a a a
ne[1]=0 a
ne[2]=1 a a
ne[3]=0 a a b
ne[4]=1 a a b a
ne[5]=2 a a b a a
ne[6]=3 a a b a a b
ne[7]=4 a a b a a b a
ne[8]=5 a a b a a b a a
ne[9]=2 a a b a a b a a a
ne[10]=2 a a b a a b a a a a
定义双指针:i 扫描模式串,j 扫描前缀。
初始化,ne[1]=0, i=2, j=0。
每轮 for 循环,i 向右走一步。
- 若 P[i]!=P[j+1],让 j 回跳到能匹配的位置,
如果找不到能匹配的位置,j 回跳到 0。 - 若 P[i]==P[j+1],让 j+1,指向匹配前缀的末尾。
- next[i] 等于 j 的值。
1 | for(int i=2,j=0;i<=n;i++){ |

模式串与主串匹配
双指针:i 扫描主串,j 扫描模式串。
初始化,i=1, j=0。
每轮 for,i 向右走一步。
- 若S[i]!=P[j+1],让 j 回跳到能匹配的位置,
如果找不到能匹配的位置,j 回跳到 0。 - 若S[i]==P[j+1],让 j 向右走一步。
- 若匹配成功,输出匹配位置。
1 | for(int i=1,j=0;i<=m;i++){ |